rio.h, rio.c是redis内部对部分io的一个封装,封装之后不管是buffer, 还是file, 还是fdset, 它们都是rio对象,有统一的write, read等函数,外部调用它们的时候不用关心 底层细节. 从这里可以学到c里面怎么来实现面向对象编程,我们会发现面向对象只是一种思想, 跟语言无关,并不需要class关键词.
先看rio.h里rio的这个结构的定义(篇幅限制,只copy部分)
struct _rio { size_t (*read)(struct _rio *, void *buf, size_t len); size_t (*write)(struct _rio *, const void *buf, size_t len); off_t (*tell)(struct _rio *); int (*flush)(struct _rio *); size_t processed_bytes; /* number of bytes read or written */ size_t max_processing_chunk; /* maximum single read or write chunk size */ union { struct { sds ptr; off_t pos; } buffer; struct { FILE *fp; off_t buffered; /* Bytes written since last fsync.
很久没有更新了,evernote里倒是攒了一堆素材,就是没整理,现在准备抽空更新了。
之前是用pelican生成网页的,后来有次pelican更新了,把一个组件都弄到一个别的repo了,
然后每次配置又得多clone几个repo了。正好最近学习go,hugo这种single binary感觉也不错,
配合travis自动更新都不需要安装什么依赖的,然后就决定迁移过来了。
travis是一个自动化的编译、打包、测试、部署平台,对开源项目免费,支持n多语言,通过自定义脚本,
感觉就是送了一个打包测试的服务器,不知道他的盈利模式是什么用的,靠少量付费用户能撑起这么多
开源项目的免费使用么?
他的工作流程大致如下:
push OR pull request to a repo ->
github notify this event to travis ->
travis clone your code and build according the configuration.
I’ll show a small peice of code at first:
:::python
>>> def foo(a=[]):
... a.append(1)
... print(a)
...
>>> foo()
[1]
>>> foo()
[1, 1]
>>> foo()
[1, 1, 1]
>>> foo
<function foo at 0x7efc48708bf8>
I was confused by this when first met it years ago. A lot of people, me
included, may think that list a should always be [1] and why it behaviors like a
global variable.
Everything is an object
We frequently see this quote but it’s not easy to understand.
In python, a function is an object too. This object is created after definition.
And the function name is just like a reference to the object. And the default
parameter of the function is also determined at the same time.
I started a small project based on tornado and mongodb last week, now I’d like
to write a summary about it since most functions are finished.
Why start this project
We used bugzilla frequently but the traffic to bugzilla is very slow.
It uses openid to login and the authentication cookies last very short.
Too many irrelevant products.
Goal of the project
Using curl to search the bugzilla easily. You can search by keywords, or email.
Can easily get latest reported bugs of a specific product.
How to?
Our bugzilla enabled the xmlrpc api so it’s very easy to fetch data using
xmlrpcclient library. I chose to store data with mongodb.
Wrote the web server based on tornado. Parsed the requests and queried the
mongodb and then wrote back the data.
Code repo:
github.com/zxdvd/scripts/tree/master/bugzilla
I didn’t use a independent repo since there isn’t too much codes.
Several months ago, my colleague got a problem that some of his virtual
machines. I dug into this problem and finally solved it.
Following is the network topology =
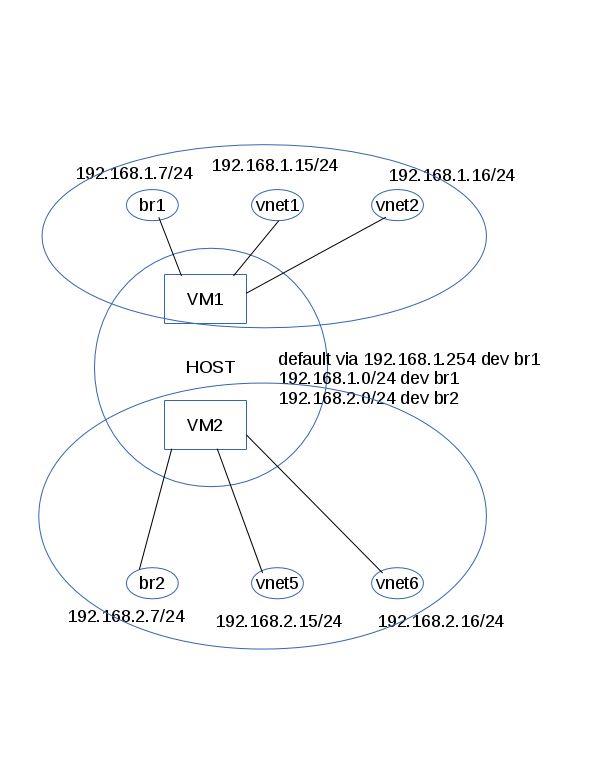
It has following problems =
The br2 and vnet5 and vnet6 can only communicate with subnet 192.168.2.0/24,
they cannot send or receive packages from other subnets.
Explanation =
Because there is only route to 192.168.2.0/24 for the br2. Let’s try to analyze
it through a ping process. If you ping 192.168.2.7 (br2) from a machine outside
of this subnet, like 192.168.1.10, below is the detailed routing path =
src to dst = 192.168.1.10 checks the destination and finds it’s in another subnet
so send it to the default gateway.
192.168.1.10 --> to gateway 192.168.1.254 OK
192.168.1.254 --> forward to 192.168.2.254 OK
192.168.2.254 --> forward to 192.168.2.7 OK
dst to src = Also 192.168.2.7 would send to default gateway, but let’s check the
default gateway of the machine. It’s default via 192.168.1.254 dev br1, so it
fails to send the package since the br1 interface won’t send a package whose
source ip address is not bounded to itself.
Now we knows that the br2 can receive packages but fail to send them to other
subnets. So how to? Add another default gateway? A machine can only have one
default gateway.
原文链接: why you don’t need to run sshd in your docker containers
今天在docker官方博客上看到一篇很好的文章,很有收获,打算翻译过来。
这篇文章讲的是不在container中使用sshd的n个理由–其实我之前很喜欢在里面开个sshd方便去check状态log之类的。
在使用docker的时候,总是有人会问“怎么进入到container里面去呢?”,然
后一些人就会说“开个sshd不就行了”。当你看完这篇文章之后你会发现sshd是不
必要的,除非你需要一个ssh server的container。
一开始大家都会禁不住去用ssh server,这看起来是最简单的方法–几乎每个
人都用过ssh的。对于我们很多人来说,ssh是一个基本技能,对各种公私钥,
无密码登陆,端口转发等等都很熟悉。有了这些基础,自然而然就会想通过sshd
进入container内部了。
现在假设你要redis server或者java webservice的docker image。考虑下下面几个问题:
- 你需要sshd来干嘛?多数情况下你可能只是需要做下备份,查看下日志,或者重启下进程、调整下配置文件,甚至用gdb、strace来调试等等。那么后面我来告诉你怎么不使用sshd来完成这些任务。